
python爬虫是干嘛的(带你全面了解爬虫)
一、什么叫爬虫
爬虫,又名“网络爬虫”,就是能够自动访问互联网并将网站内容下载下来的程序。它也是搜索引擎的基础,像百度和GOOGLE都是凭借强大的网络爬虫,来检索海量的互联网信息的然后存储到云端,为网友提供优质的搜索服务的。

二、爬虫有什么用
你可能会说,除了做搜索引擎的公司,学爬虫有什么用呢?哈哈,总算有人问到点子上了。打个比方吧:企业A建了个用户论坛,很多用户在论坛上留言讲自己的使用体验等等。现在A需要了解用户需求,分析用户偏好,为下一轮产品迭代更新做准备。那么数据如何获取,当然是需要爬虫软件从论坛上获取咯。所以除了百度、GOOGLE之外,很多企业都在高薪招聘爬虫工程师。你到任何招聘网站上搜“爬虫工程师”看看岗位数量和薪资范围就懂爬虫有多热门了。
三、爬虫的原理
发起请求:通过HTTP协议向目标站点发送请求(一个request),然后等待目标站点服务器的响应。
获取响应内容:如果服务器能正常响应,会得到一个Response。Response的内容便是所要获取的页面内容,响应的内容可能有HTML,Json串,二进制数据(如图片视频)等等。
解析内容:得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析;可能是Json,可以直接转为Json对象解析;可能是二进制数据,可以做保存或者进一步的处理。
保存数据:数据解析完成后,将保存下来。既可以存为文本文档、可以存到数据库中。
四、Python爬虫实例
前面介绍了爬虫的定义、作用、原理等信息,相信有不少小伙伴已经开始对爬虫感兴趣了,准备跃跃欲试呢。那现在就来上“干货”,直接贴上一段简单Python爬虫的代码:
1.前期准备工作:安装Python环境、安装PYCHARM软件、安装MYSQL数据库、新建数据库exam、在exam中建一张用于存放爬虫结果的表格house[SQL语句:create table house(price varchar(88),unit varchar(88),area varchar(88));]
2.爬虫的目标:爬取链家租房网上(url: https://bj.lianjia.com/zufang/)首页中所有链接里的房源的价格、单位及面积,然后将爬虫结构存到数据库中。
3.爬虫源代码:如下
import requests #请求URL页面内容
from bs4 import BeautifulSoup #获取页面元素
import pymysql #链接数据库
import time #时间函数
import lxml #解析库(支持HTML\XML解析,支持XPATH解析)
#get_page 函数作用:通过requests的get方法得到url链接的内容,再整合成BeautifulSoup可以处理的格式
def get_page(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
return soup
#get_links 函数的作用:获取列表页所有租房链接
def get_links(link_url):
soup = get_page(link_url)
links_div = soup.find_all('div',class_="pic-panel")
links=[div.a.get('href') for div in links_div]
return links
#get_house_info函数作用是:获取某一个租房页面的信息:价格、单位、面积等
def get_house_info(house_url):
soup = get_page(house_url)
price =soup.find('span',class_='total').text
unit = soup.find('span',class_='unit').text.strip()
area = 'test' #这里area字段我们自定义一个test做测试
info = {
'价格':price,
'单位':unit,
'面积':area
}
return info
#数据库的配置信息写到字典
DataBase ={
'host': '127.0.0.1',
'database': 'exam',
'user' : 'root',
'password' : 'root',
'charset' :'utf8mb4'}
#链接数据库
def get_db(setting):
return pymysql.connect(**setting)
#向数据库插入爬虫得到的数据
def insert(db,house):
values = "'{}',"*2 + "'{}'"
sql_values = values.format(house['价格'],house['单位'],house['面积'])
sql ="""
insert into house(price,unit,area) values({})
""".format(sql_values)
cursor = db.cursor()
cursor.execute(sql)
db.commit()
#主程序流程:1.连接数据库 2.得到各个房源信息的URL列表 3.FOR循环从第一个URL开始获取房源具体信息(价格等)4.一条一条地插入数据库
db = get_db(DataBase)
links = get_links('https://bj.lianjia.com/zufang/')
for link in links:
time.sleep(2)
house = get_house_info(link)
insert(db,house)
首先,“工欲善其事必先利其器”,用Python写爬虫程序也是一样的道理,写爬虫过程中需要导入各种库文件,正是这些及其有用的库文件帮我们完成了爬虫的大部分工作,我们只需要调取相关的借口函数即可。导入的格式就是import库文件名。
这里要注意的是在PYCHARM里安装库文件,可以通过光标放在库文件名称上,同时按ctrl+alt 键的方式来安装,也可以通过命令行(Pip install 库文件名)的方式安装,如果安装失败或者没有安装,那么后续爬虫程序肯定会报错的。在这段代码里,程序前五行都是导入相关的库文件:requests用于请求URL页面内容;BeautifulSoup用来解析页面元素;pymysql用于连接数据库;time包含各种时间函数;lxml是一个解析库,用于解析HTML、XML格式的文件,同时它也支持XPATH解析。
其次,我们从代码最后的主程序开始看整个爬虫流程:
通过get_db函数连接数据库。再深入到get_db函数内部,可以看到是通过调用
Pymysql的connect函数来实现数据库的连接的,这里**seting是Python收集关键字参数的一种方式,我们把数据库的连接信息写到一个字典DataBase里了,将字典里的信息传给connect做实参。
通过get_links函数,获取链家网租房首页的所有房源的链接。所有房源的链接以列表形式存在Links里。get_links函数先通过requests请求得到链家网首页页面的内容,再通过BeautifuSoup的接口来整理内容的格式,变成它可以处理的格式。最后通过电泳find_all 函数找到所有包含图片的div样式,再通过一个for循环来获得所有div样式里包含的超链接页签(a)的内容(也就是 href 属性的内容),所有超链接都存放在列表links中。
通过FOR循环,来遍历links中的所有链接(比如其中一个链接是:https://bj.lianjia.com/zufang/101101570737.html)
用和2)同样的方法,通过使用find函数进行元素定位获得3)中链接里的价格、单位、面积信息,将这些信息写到一个字典Info里面。
调用insert函数将某一个链接里得到的Info信息写入数据库的house表中去。深入到insert函数内部,我们可以知道它是通过数据库的游标函数cursor()来执行一段SQL语句然后数据库进行commit操作来实现响应功能。这里SQL语句的写法比较特殊,用
到了format函数来进行格式化,这样做是为了便于函数的复用。
最后,运行一下爬虫代码,可以看到链家网的首页所有房源的信息都写入到数据里了。(注:test是我手动指定的测试字符串)
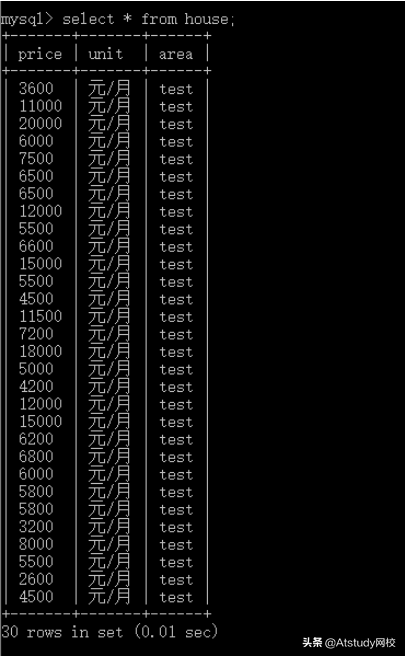
后记:其实Python爬虫并不难,熟悉整个爬虫流程之后,就是一些细节问题需要注意,比如如何获取页面元素、如何构建SQL语句等等。遇到问题不要慌,看IDE的提示就可以一个个地消灭BUG,最终得到我们预期的结构。
原文地址:https://tangjiusheng.cn/it/3905.html