
哈夫曼编码运用到了哪种数据结构(一文了解哈夫曼编码)
哈夫曼(Huffman)编码是上个世纪五十年代由哈夫曼教授研制开发的,它借助了数据结构当中的树型结构,在哈夫曼算法的支持下构造出一棵最优二叉树,我们把这类树命名为哈夫曼树。因此,准确地说,哈夫曼编码是在哈夫曼树的基础之上构造出来的一种编码形式,主要用于数据编码压缩,在多媒体技术、编解码技术、通信技术等领域有着非常广泛的应用。
1 通信中的编码问题
通信中的信息传输,一般都需要进行编码,接收方收到后,按照编码的逆过程,再将信息还原为原来的形式。
最常用的传播通道是二元通道,即可传输两个基本符号的通道,常用0、表示。
例如,将传送的文字转换成二进制的字符串,用0,1码的不同排列来表示字符。假设需传送的报文为“AFTER DATA EAR ARE ART AREA”,这里用到的字符集为“A,E,R,T,F,D”,各字母出现的次数为{8,4,5,3,1,1}。现要求为这些字母设计编码。要区别6个字母,最简单的二进制编码方式是等长编码,固定采用3位二进制,可分别用000、001、010、011、100、101对“A,E,R,T,F,D”进行编码发送,当对方接收报文时再按照三位一分进行译码。显然编码的长度取决报文中不同字符的个数。若报文中可能出现26个不同字符,则固定编码长度为5。然而,传送报文时总是希望总长度尽可能短。在实际应用中,各个字符的出现频度或使用次数是不相同的,如A、B、C的使用频率远远高于X、Y、Z,自然会想到设计编码时,让使用频率高的用短码,使用频率低的用长码,以优化整个报文编码。
1951年,哈夫曼和他在MIT信息论的同学需要选择是完成学期报告还是期末考试。导师Robert M. Fano给他们的学期报告的题目是,寻找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,哈夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。由于这个算法,学生终于青出于蓝,超过了他那曾经和信息论创立者香农共同研究过类似编码的导师。哈夫曼使用自底向上的方法构建二叉树,避免了次优算法Shannon-Fano编码的最大弊端──自顶向下构建树。
1952年,Huffman在Proceedings of the I.R.E上发表了“A Method for the Construction of Minimum-Redundancy Codes"(一种构建极小冗余编码的方法)一文来阐述这个编码算法。
2 哈夫曼树
哈夫曼树,也就是最优二叉树,是带权路径长度最小的二叉树,经常应用于数据压缩。
设某二叉树有m个叶子结点,每个叶子结点分别赋予一个权值,用wi表示(i表示第i个结点),li表示第i个结点的路径长度。那么该二叉树的带权路径长度WPL(Weight Path Length)定义为:
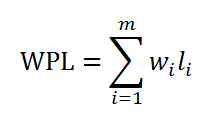
如下面的二叉树就是两棵叶子结点赋了权值的二叉树。

计算上面左图的二叉树的带权路径长度:
叶子结点权值W={2,8,6,3}
对应结点的路径长度L={2,3,3,1}
WPL = {2,8,6,3} * {2,3,3,1} =49
如果二权树的图形相同,只是某些叶子结点相互调换权值,二叉树的带权路径长度会相同通常也会不同:
上面右图的二叉树的带权路径长度:
叶子结点权值W={8,2,3,6}
对应结点的路径长度L={2,3,3,1}
WPL = {8,2,3,6} * {2,3,3,1} =37
当然,同样的带权值四个叶子节点{2,8,6,3},可以构造不同的树,对应的各叶子结点的路径长度肯定也会不同,所以二叉树的带权路径长度也会不同。
那现在的问题是,对于给定的一组权值,如何构造二叉树,使得带权路径长度最小?
2.1 将给定的权值按照从小到大的顺序排列(w1,w2,…,wn),然后构造出森林F=(T1,T2,…Tn),其中第棵树都是左、右子树均为空的二叉树,Ti的权值为Wi。
2.2 把森林F中根结点权值最小的两棵二叉树T1,T2作为左、右叶子结点合并为一棵新的二叉树T,令T的根结点的权值为T1,T2两个结点的权值之和,然后将T按照其根结点权值大小加入到森林F中,同时从F中删除T1,T2这两棵二叉树;
2.3 重复上述2.2步骤,直到构造出一棵二叉树为止。
权值四个叶子节点{2,8,6,3}构造的思路可图示如下:
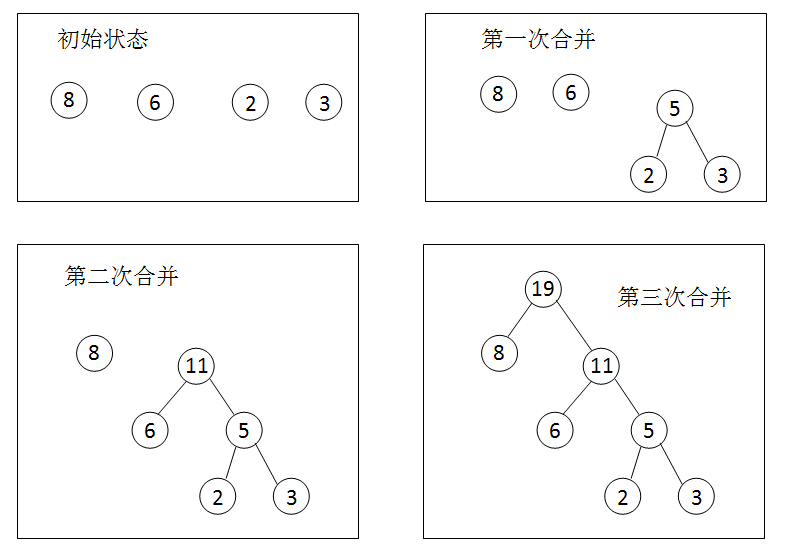
上图的二叉树的带权路径长度:
叶子结点权值W={8,6,2,3}
对应结点的路径长度L={1,2,3,3}
WPL = {8,6,2,3} * {1,2,3,3} =35
按上述思路构造的二叉树就是哈夫曼树,根据给定的一组权值,其带权路径长度最小。
给定n个带权值的叶子结点,构造一棵二叉树,若带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
3 哈夫曼编码
利用哈夫曼树对数据进行二进制编码称为哈夫曼编码。
假设要对字符串"this is a test"进行编码,(t, h, i, s, a, e, 空格)就组成了一个字符集D,各字符重复的频率组成一组权值W(3, 1, 2, 3, 1, 1, 3),以该组权值构造一棵哈夫曼树。从根节点到叶节点di的路径上,每经过一条左树枝,取二进制值0,每经过一条右树枝,取二进制1,于是从根结点到叶结点di的路径上得到由二进制0和1构成的二进制序列即为字符di对应的哈夫曼编码。

字符集的哈夫曼编码为:
| 字符di | t | h | i | s | a | e | 空格符 |
| 频率wi | 3 | 1 | 2 | 3 | 1 | 1 | 3 |
| 编码 | 10 | 00000 | 001 | 11 | 00001 | 0001 | 01 |
可以看出,重复频率越高的字符,其哈夫曼编码越短。相反,出现次数越少的字符,其编码越长。这样就从整体上保证了报文的长度最短。
因为哈夫曼编码是不等长编码,即不同字符的编码长度可能不同,所以必须保证任何一个字符的编码都不是另一个字符编码的前缀,这样当编码写到一起时才能正确区分每个字符的编码,这样的编码称为前缀编码。由于哈夫曼编码是基于哈夫曼树生成的,而代表每个字符的结点都是哈夫叶子结点,不可能出现在从根结点到另一个字符的路径上,从而保证了哈夫曼编码一定是前缀编码。这样也就避免了解码过程中的二叉性问题。
哈夫曼编码是可变字长编码(VLC)的一种。 Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就称Huffman编码。
哈夫曼码的码字(各符号的代码)是异前置码字,即任一码字不会是另一码字的前面部分,这使各码字可以连在一起传送,中间不需另加隔离符号,只要传送时不出错,收端仍可分离各个码字,不致混淆。
4 哈夫曼编码是如何来实现数据的压缩和解压缩的呢?
众所周知,在计算机当中,数据的存储和加工都是以字节作为基本单位的,一个西文字符要通过一个字节来表达,而一个汉字就要用两个字节,我们把这种每一个字符都通过相同的字节数来表达的编码形式称为定长编码。以西文为例,例如我们要在计算机当中存储这样的一句话:I am a teacher。就需要15个字节,也就是120个二进制位的数据来实现。与这种定长编码不同的是,哈夫曼编码是一种变长编码。它根据字符出现的概率来构造平均长度最短的编码。换句话说如果一个字符在一段文档当中出现的次数多,它的编码就相应的短,如果一个字符在一段文档当中出现的次数少,它的编码就相应的长。当编码中,各码字的长度严格按照对应符号出现的概率大小进行逆序排列时,则编码的平均长度是最小的。这就是哈夫曼编码实现数据压缩的基本原理。要想得到一段数据的哈夫曼编码,需要用到三个步骤:第一步:扫描需编码的数据,统计原数据中各字符出现的概率。第二步:利用得到的概率值创建哈夫曼树。第三步:对哈夫曼树进行编码,并把编码后得到的码字存储起来。
因为定长编码已经用相同的位数这个条件保证了任一个字符的编码都不会成为其它编码的前缀,所以这种情况只会出现在变长编码当中,要想避免这种情况,我们就必须用一个条件来制约定长编码,这个条件就是要想成为压缩编码,变长编码就必须是前缀编码。什么是前缀编码呢?所谓的前缀编码就是任何一个字符的编码都不能是另一个字符编码的前缀。
那么哈夫曼编码是否是前缀编码呢?观察a、b、c、d构成的编码树,可以发现b之所以成为c的前缀,是因为在这棵树上,b成为了c的父结点,从在哈夫曼树当中,原文档中的数据字符全都分布在这棵哈夫曼树的叶子位置,从而保证了哈夫曼编码当中的任何一个字符的编码都不能是另一个字符编码的前缀。也就是说哈夫曼编码是一种前缀编码,也就保证了解压缩过程当中译码的准确性。哈夫曼编码的解压缩过程也相对简单,就是将编码严格按照哈夫曼树进行翻译就可以了,例如遇到000,就可以顺着哈夫曼树找到I,遇到101就可以顺着哈夫曼树找到空格,以此类推,我们就可以很顺利的找到原来所有的字符。哈夫曼编码是一种一致性编码,有着非常广泛的应用,例如在JPEG文件中,就应用了哈夫曼编码来实现最后一步的压缩;在数字电视大力发展的今天,哈夫曼编码成为了视频信号的主要压缩方式。应当说,哈夫曼编码出现,结束了熵编码不能实现最短编码的历史,也使哈夫曼编码成为一种非常重要的无损编码。
哈夫曼方法的最大缺点就是它需要对原始数据进行两遍扫描:第一遍统计原始数据中各字符出现的频率,利用得到的频率值创建哈夫曼树并将树的有关信息保存起来,便于解压时使用;第二遍则根据前面得到的哈夫曼树对原始数据进行编码,并将编码信息存储起来。这样如果用于网络通信中,将会引起较大的延时;对于文件压缩这样的应用场合,额外的磁盘访间将会降低该算法的数据压缩速度。
为使不等长编码为前缀编码(即要求一个字符的编码不能是另一个字符编码的前缀),可用字符集中的每个字符作为叶子结点生成一棵编码二叉树。为了获得传送报文的最短长度,可将每个字符的出现频率作为字符结点的权值赋予该结点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度效果上就是传送报文的最短长度。因此,求传送报文的最短长度问题转化为求由字符集中的所有字符作为叶子结点,由字符出现频率作为其权值所产生的哈夫曼树的问题。利用哈夫曼树来设计二进制的前缀编码,既满足前缀编码的条件,又保证报文编码总长最短。
在图像压缩时,霍夫曼编码的基本方法是先对图像数据扫描一遍,计算出各种像素出现的概率,按概率的大小指定不同长度的唯一码字,由此得到一张该图像的霍夫曼码表。编码后的图像数据记录的是每个像素的码字,而码字与实际像素值的对应关系记录在码表中。
5 一个哈夫曼树的实例




运行效果:

6 一个哈夫曼编码的实例




运行效果:

附原码1:
#include <iostream>
#include <iomanip>
using namespace std;
//哈夫曼树的存储表示
typedef struct
{
int weight; // 权值
int parent, lChild, rChild; // 双亲及左右孩子的下标
}HTNode, *HuffmanTree;
// 选择权值最小的两颗树
void SelectMin(HuffmanTree hT, int n, int &s1, int &s2)
{
s1 = s2 = 0;
int i;
for(i = 1; i < n; ++ i){
if(0 == hT[i].parent){
if(0 == s1){
s1 = i;
}
else{
s2 = i;
break;
}
}
}
if(hT[s1].weight > hT[s2].weight){
int t = s1;
s1 = s2;
s2 = t;
}
for(i += 1; i < n; ++ i){
if(0 == hT[i].parent){
if(hT[i].weight < hT[s1].weight){
s2 = s1;
s1 = i;
}else if(hT[i].weight < hT[s2].weight){
s2 = i;
}
}
}
}
// 构造有n个权值(叶子节点)的哈夫曼树
void CreateHufmanTree(HuffmanTree &hT)
{
int n, m;
cout << "输入需要构造哈夫曼树的叶子结点数量,如4:"<<endl;
cin >> n;
m = 2*n - 1;
hT = new HTNode[m + 1]; // 0号节点不使用
for(int i = 1; i <= m; ++ i){
hT[i].parent = hT[i].lChild = hT[i].rChild = 0;
}
cout << "输入权值,如8 6 2 3:" <<endl;
for(int j = 1; j <= n; ++ j){
cin >> hT[j].weight; // 输入权值
}
hT[0].weight = m; // 用0号节点保存节点数量
/****** 初始化完毕, 创建哈夫曼树 ******/
for(int k = n + 1; k <= m; ++ k){
int s1, s2;
SelectMin(hT, k, s1, s2);
hT[s1].parent = hT[s2].parent = k;
hT[k].lChild = s1; hT[k].rChild = s2; // 作为新节点的孩子
hT[k].weight = hT[s1].weight + hT[s2].weight; // 新节点为左右孩子节点权值之和
}
}
int HuffmanTreeWPL_(HuffmanTree hT, int i, int deepth)
{
if(hT[i].lChild == 0 && hT[i].rChild == 0){
return hT[i].weight * deepth;
}
else{
return HuffmanTreeWPL_(hT, hT[i].lChild, deepth + 1) + HuffmanTreeWPL_(hT, hT[i].rChild, deepth + 1);
}
}
// 计算WPL(带权路径长度)
int HuffmanTreeWPL(HuffmanTree hT)
{
return HuffmanTreeWPL_(hT, hT[0].weight, 0);
}
// 输出哈夫曼树各节点的状态
void Print(HuffmanTree hT)
{
cout << "index weight parent lChild rChild" << endl;
cout << left; // 左对齐输出
for(int i = 1, m = hT[0].weight; i <= m; ++ i){
cout << setw(5) << i << " ";
cout << setw(6) << hT[i].weight << " ";
cout << setw(6) << hT[i].parent << " ";
cout << setw(6) << hT[i].lChild << " ";
cout << setw(6) << hT[i].rChild << endl;
}
}
// 销毁哈夫曼树
void DestoryHuffmanTree(HuffmanTree &hT)
{
delete[] hT;
hT = NULL;
}
int main()
{
HuffmanTree hT;
CreateHufmanTree(hT);
Print(hT);
cout << "WPL = " << HuffmanTreeWPL(hT) << endl;
DestoryHuffmanTree(hT);
system("pause");
return 0;
}
附原码2:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<queue>
using namespace std;
typedef struct node{
char ch; //存储该节点表示的字符,只有叶子节点用的到
int val; //记录该节点的权值
struct node *self,*left,*right; //三个指针,分别用于记录自己的地址,左孩子的地址和右孩子的地址
friend bool operator <(const node &a,const node &b) //运算符重载,定义优先队列的比较结构
{
return a.val>b.val; //这里是权值小的优先出队列
}
}node;
priority_queue<node> p; //定义优先队列
char res[30]; //用于记录哈夫曼编码
void dfs(node *root,int level) //打印字符和对应的哈夫曼编码
{
if(root->left==root->right) //叶子节点的左孩子地址一定等于右孩子地址,且一定都为NULL;叶子节点记录有字符
{
if(level==0) //“AAAAA”这种只有一字符的情况
{
res[0]='0';
level++;
}
res[level]='\0'; //字符数组以'\0'结束
printf("%c=>%s\n",root->ch,res);
}
else
{
res[level]='0'; //左分支为0
dfs(root->left,level+1);
res[level]='1'; //右分支为1
dfs(root->right,level+1);
}
}
void huffman(int *hash) //构建哈夫曼树
{
node *root,fir,sec;
for(int i=0;i<26;i++) //程序只能处理全为大写英文字符的信息串,故哈希也只有26个
{
if(!hash[i]) //对应字母在text中未出现
continue;
root=(node *)malloc(sizeof(node)); //开辟节点
root->self=root; //记录自己的地址,方便父节点连接自己
root->left=root->right=NULL; //该节点是叶子节点,左右孩子地址均为NULL
root->ch='A'+i; //记录该节点表示的字符
root->val=hash[i]; //记录该字符的权值
p.push(*root); //将该节点压入优先队列
}
//下面循环模拟建树过程,每次取出两个最小的节点合并后重新压入队列
//当队列中剩余节点数量为1时,哈夫曼树构建完成
while(p.size()>1)
{
fir=p.top();p.pop(); //取出最小的节点
sec=p.top();p.pop(); //取出次小的节点
root=(node *)malloc(sizeof(node)); //构建新节点,将其作为fir,sec的父节点
root->self=root; //记录自己的地址,方便该节点的父节点连接
root->left=fir.self; //记录左孩子节点地址
root->right=sec.self; //记录右孩子节点地址
root->val=fir.val+sec.val;//该节点权值为两孩子权值之和
p.push(*root); //将新节点压入队列
}
fir=p.top();p.pop(); //弹出哈夫曼树的根节点
dfs(fir.self,0); //输出叶子节点记录的字符和对应的哈夫曼编码
}
int main()
{
char text[100];
int hash[30];
memset(hash,0,sizeof(hash)); //哈希数组初始化全为0
printf("输入信息串text,全部要求是大字字母,不能有空格,如THISISATEST:\n");
scanf("%s",text); //读入信息串text
for(int i=0;text[i]!='\0';i++)//通过哈希求每个字符的出现次数
{
hash[text[i]-'A']++; //程序假设运行的全为英文大写字母
}
huffman(hash);
getchar();getchar();
system("pause");
return 0;
}
-End-
原文地址:https://tangjiusheng.cn/it/5393.html